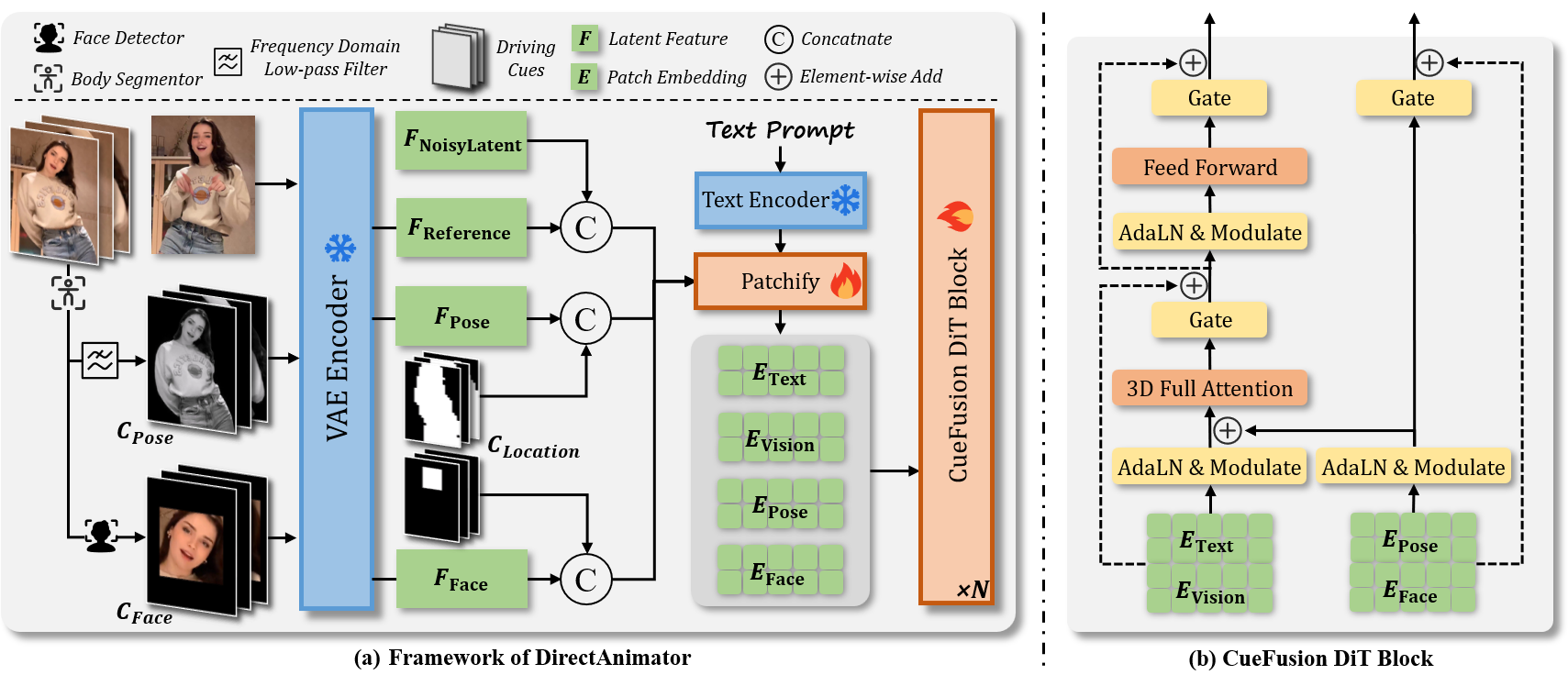
3. Same2X Training Strategy
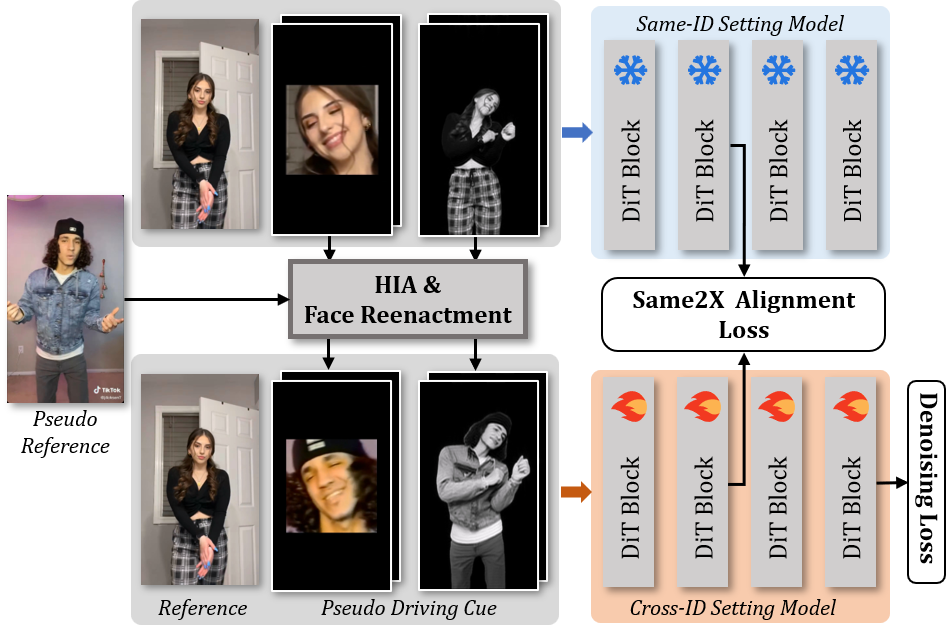
Figure 4. Overview of the Same2X training strategy.
To ease training in the cross-ID setting, we propose the Same2X training strategy, whose pipeline is illustrated in Figure 4. The strategy consists of a same-ID and a cross-ID training stage. In the same-ID training stage, we train the model using pairs of reference images and driving videos from the same video clip. In the cross-ID stage, we generate pseudo driving cues from same-ID data using StableAnimator and Face-Adapter to simulate cross-ID conditions.
During the cross-ID training stage, the model is supervised not only by denoising loss but also by feature alignment signals from the model trained under same-ID setting. To this end, we introduce a Same2X Alignment Loss (S2X Loss) to guide the feature dynamics:
\[
\mathcal{L}_{\text{S2X}}(\theta_S, \theta_X) := -\mathbb{E}_{x, c, \epsilon, t} \left[ \frac{1}{N} \sum_{n=1}^{N} \text{sim}\left(h_s^{[D\_n]}, h_x^{[D\_n]}\right) \right]
\]
Here, \( \theta_S \) and \( \theta_X \) denote the model trained under same-ID and cross-ID settings, respectively. \( h_s^{[D\_n]} \) and \( h_x^{[D\_n]} \) represent the patch embeddings at the \( D \)-th DiT block for the same-ID and cross-ID models, and \( n \) indexes the patch tokens. The function \( \text{sim}(\cdot, \cdot) \) measures cosine similarity.
We combine the S2X Loss and denoising loss to train DirectAnimator, with the overall loss function in the cross-ID training stage formulated as:
\[
\mathcal{L} := \mathcal{L}_{\text{Denoising}} + \lambda \cdot \mathcal{L}_{\text{S2X}}
\]
where \( \lambda \) is a factor controlling the contribution of the S2X loss. As demonstrated in Figure 1, the Same2X training strategy significantly accelerates convergence in the cross-ID setting by alleviating the learning difficulty. To the best of our knowledge, this is the first approach to leverage feature alignment of different setting for training HIA models.